

Large language models, or LLMs, are setting new standards in the development of artificial intelligence. Leveraging deep learning techniques and training on enormous text datasets, today’s LLMs can not only generate text but also grasp its meaning in ways previously impossible for machines just a few years ago. The applications of LLMs span nearly every language-dependent domain, from customer service and programming to scientific research.
This article explains how LLMs work, identifies challenges associated with their deployment, and explores areas where they find practical applications.
What are large language models?
Simply put, an LLM is an advanced artificial intelligence system designed to understand, generate, and analyze natural language. It utilizes deep learning techniques, primarily based on the transformer architecture. LLMs are trained on large volumes of textual data sourced from the Internet, including books, technical documentation, source code, and numerous other repositories. This extensive training provides them with general knowledge of language structures, textual organization, and conceptual relationships.
Technically, LLMs excel in natural language processing (NLP) tasks such as text generation, translation, summarization, sentiment analysis, question answering, code generation, and conversational AI. The transformer architecture is central to these models, particularly its self-attention mechanism, which enables analysis of word meanings within the full context of an input sequence rather than relying solely on adjacent words.
At the computational level, these models are deep neural networks: systems inspired by the architecture of the human brain. They consist of numerous layers of artificial “neurons” that collaboratively learn data representations and convert them into accurate responses. Crucially, these systems rely on parameters, i.e., internal values, that are optimized during training. The quantity and structure of these parameters significantly determine a model’s ability to recognize patterns and make precise linguistic decisions.
In the context of large models, parameter counts reach into the billions, and the latest systems even exceed trillions of parameters. It’s precisely this immense scale, rather than the algorithms alone, that enables step-by-step reasoning, high-quality translation, effective code generation, and surprisingly human-like responses.
As of 2025, the concept of “large language models” has expanded beyond mere text. The newest models—such as GPT-4o, Claude 3, Gemini 2.5 Pro, and Llama 4—are multimodal. This means they can analyze not just text, but also programming code, images, audio, and even video. Consequently, their applications have broadened significantly in recent years. Because of that, such models are also called foundation models.
Simultaneously, model efficiency is becoming increasingly vital. Architectures employing mixture-of-experts (MoE) techniques, activating only subsets of parameters per query, are gaining popularity. This approach enables the creation of models with massive “capacity” without linearly increasing computational costs. A notable example is Llama 4 Maverick, an open-source model boasting over 400 billion parameters, of which only about 17 billion are activated at any given time.
How do large language models work?
At the heart of an LLM lies the transformer architecture, a groundbreaking innovation introduced in the seminal 2017 paper Attention is All You Need by Ashish Vaswani et al. This architecture, built around two primary components, the encoder and the decoder, leverages a technique called self-attention, enabling scalable, context-aware text processing and generation.
The process begins with tokenization—the breaking down of text into smaller units known as tokens. A token might represent an entire word, a single character, or, most commonly, a fragment of a word. These tokens form the basic building blocks for subsequent linguistic operations. After tokenization, each token is transformed into a numerical representation known as an embedding, allowing the model to perform mathematical computations internally.
Embeddings are dense numerical vectors that encode semantic, syntactic, and contextual properties of each token. To help the model capture the order of words in a sentence, these embeddings are combined with positional encodings—mathematical patterns that assign unique position-based values to each token. This enables the model to recognize, for example, that the word “cat” in “The cat chases the dog” appears near the beginning of the sentence rather than at the end.
After tokenization and embedding (with positional information added), the sequence is passed into the encoder. Within the encoder, the self-attention mechanism allows the model to compute how much focus each token should place on every other token in the sequence. This enables the model to build context-aware representations, capturing both short-range dependencies (like between “cat” and “chases”) and long-range relationships (such as connections across entire paragraphs or documents).
The subsequent step involves the decoder, which generates output text based on information processed by the encoder. Utilizing accumulated contextual insights, the decoder progressively produces coherent and contextually relevant text tailored precisely to the user’s query, instructions, or task request. It is within the decoder that the model selects subsequent words, carefully considering syntax and meaning.
It’s this sophisticated, context-sensitive architecture that empowers today’s language models to perform tasks far beyond translation, summarization, or answering queries. Modern LLMs can now effectively write code, hold conversations, and analyze data in real-time, marking an unprecedented milestone in artificial intelligence.
Read more on AI:
8 generative AI trends to watch in 2025
Generative AI in pharma: A virtual assistant for smart sales
Leveraging LLM function calling to harness real-time knowledge
Will large context windows kill RAG pipelines?
What is synthetic data and how it can help us break the data wall?
Boosting productivity with an AI personal assistant—three real-life use cases
Finding the best LLM—a guide for 2024
Generative AI implementation in business: how to do it responsibly and ethically
Ten business use cases for generative AI virtual assistants
Generative AI in knowledge management—a practical solution for enterprisesCurbing ChatGPT hallucinations with retrieval augmented generation (RAG)
Generative artificial intelligence and LLMs
In the context of solutions like ChatGPT, the term generative artificial intelligence (generative AI or GenAI) is frequently used. It’s therefore worth clarifying how this term relates to LLMs and what distinguishes the two.
Generative AI is a broad concept encompassing an entire class of artificial intelligence models capable of creating new content, regardless of the format. This includes systems that generate text, code, images, music, and even video. Thus, one could say that GenAI acts as an umbrella term covering various model types that share a common trait: the ability to create, rather than merely analyze.
Within this broad set of technologies, LLMs represent a specialized subgroup focused specifically on NLP. LLMs are designed and trained specifically to generate text that is coherent, grammatically correct, and semantically meaningful. They learn not only the rules of syntax and punctuation but also style, context, language registers, and subtle nuances of expression. This makes their output fluid, logical, and contextually appropriate, and often indistinguishable from human-written text.
A significant milestone for generative AI was the introduction of the GPT-3 model, which gained widespread recognition due to its capabilities in conversation, essay writing, and translation. Its successor, GPT-4, has advanced even further. This multimodal model can process not only textual data but also images as input. Consequently, GPT-4 can understand sentences as well as pictures, charts, and illustrations, significantly expanding its applications.
In summary, every LLM is a form of generative AI, but not all generative AI models are LLMs.
Training of large language models
The training process for an LLM comprises three main stages: pretraining, fine-tuning, and alignment. Additionally, precise control of a model’s behavior can be achieved through carefully structured prompts—a technique known as prompt engineering.
Pretraining
Pretraining constitutes the foundational stage in the development of an LLM. During this phase, the model learns to understand natural language and how to generate text. It is at this stage that AI absorbs general linguistic patterns, semantic rules, syntax, and basic knowledge about the world, enabling effective performance on tasks like translation, writing, summarizing, or conversation.
Models are trained on massive datasets—counted in trillions of tokens—and can possess hundreds of billions or even trillions of parameters. This training process relies on self-supervised learning (also known as unsupervised learning), where models predict subsequent words or text fragments based on context. Through this, models build internal representations of language and world knowledge, simultaneously developing capabilities for logical reasoning, programming, and understanding complex instructions. The larger the dataset and parameters, the more frequently emergent abilities appear, including unexpected abilities such as step-by-step reasoning, emotional interpretation, or explanation of phenomena.
Since 2023, leading model developers have adopted a multimodal approach, integrating different data types even at the pretraining stage. Modern models simultaneously learn from text, images, audio, and video data. Examples include Google Gemini and GPT-4o, which form common conceptual representations regardless of the input data format. In 2025, nearly all top LLMs are capable of processing or generating multimodal content, significantly expanding their applications, such as visual code analysis, meme interpretation, and synthesizing audiovisual descriptions. Multimodality has thus become the new standard, marking a departure from earlier generations trained exclusively on textual data.
In tandem with increasing model scales and data volumes, pretraining costs have soared into tens of millions of dollars per training run. Consequently, the industry seeks methods that are more efficient, both economically and environmentally. Techniques such as coreset selection, involving choosing smaller, representative subsets of data, have become increasingly popular. These allow comparable quality training at reduced costs. Another alternative is using synthetic data generated by previous LLM models, a method known as self-feeding or knowledge distillation. Such approaches reduce reliance on continually sourcing billions of tokens from the Internet while maintaining training quality.
As data volumes expand, awareness about their qualitative impact on model effectiveness also grows. Experiences with earlier LLM versions, which exhibited hallucinations or biases, have led to stricter data selection criteria. GPT-4, for example, was trained on carefully curated datasets comprising high-quality Internet content and technical documentation. Currently, data quality is becoming as important as quantity. Processes for filtering, validation, and ensuring linguistic diversity are increasingly emphasized, improving the alignment of models with real-world tasks and reducing the risk of generating inaccurate information.
Fine-tuning
Although pretraining allows an LLM to develop a general understanding of language, it isn’t enough to enable the execution of specialized tasks with the required precision. Therefore, the next stage is known as fine-tuning, a process of adapting the model to specific applications. This involves adjusting model parameters using new datasets that reflect scenarios and goals particular to a given application. Examples include datasets for recognizing emotions in texts or generating emails consistent with a specified communication style.
In fine-tuning, the quality of data is crucial. Training datasets must not only be extensive—often encompassing thousands of carefully prepared examples—but also appropriately cleaned, formatted, and matched to real-world usage scenarios. In sentiment analysis, it’s important to cover a broad spectrum of emotions and sources. For email generation, the precise representation of tone, linguistic register, and typical sentence structures is vital. The better constructed the dataset, the greater the likelihood the model will perform accurately, consistently, and in the desired style.
Today, fine-tuning has become a standard practice in deploying LLMs, both open-source models and commercial environments. Major providers such as OpenAI offer the ability to fine-tune even proprietary models, like GPT-3.5 Turbo or GPT-4o, via API interfaces. This enables companies to build personalized conversational assistants, supporting customer service, document analysis, or daily operational tasks.
Methods of parameter-efficient fine-tuning (PEFT), such as low-rank adaptation (LoRA), are increasingly popular. These significantly reduce computational costs by training only small, additional matrices, which are then integrated into an existing model. As a result, even 70-billion-parameter models can be fine-tuned on a single GPU, making fine-tuning feasible in local, academic, and resource-limited settings.
Alignment
Following the fine-tuning stage is alignment, the aim of which is to adjust a model’s behavior according to specific ethical norms and human values. In practice, this means teaching the model not only “what” to say but also “how” and “why.” One commonly used method is reinforcement learning from human feedback (RLHF), where human evaluators provide positive signals to reinforce desired responses and shape preferred behavioral patterns.
The alignment process also uses more formalized techniques, such as direct policy optimization (DPO) and knowledge transfer optimization (KTO), which precisely define the ethical framework within which the model operates. Increasingly, the mechanism of self-play, where the model engages in dialogue with itself, is employed to further enhance decision-making capabilities and consistency in complex contexts.
Such rigorous alignment is particularly important in sensitive applications like medicine, legal advice, or customer service, where incorrect or unethical responses can have tangible consequences. Thus, technical safety alone is insufficient—predictability, transparency, and alignment with societal values become crucial.
In recent years, constitutional AI has gained prominence. This is a method where the model does not solely rely on human judgment “case by case” but learns from a set of explicit principles. Such rules might include that the model ” should not offend,” “should justify its refusals,” or “should operate transparently.” Based on these principles, an AI generates self-criticism, evaluates its own outputs, and modifies them to better align with the set objectives. This entire process is supported by other models that assess which version of an answer aligns best with the accepted “constitution.” This approach, known as reinforcement learning from AI feedback (RLAIF), enables alignment to scale with minimal human involvement, reducing toxicity, logical errors, and unjustified refusals.
A unique challenge for modern LLMs involves very long conversational contexts, characteristic of models such as GPT-4o or Claude 3. In extended dialogues, models may exhibit sycophancy, blindly agreeing with the user even if this contradicts previously established guidelines. To prevent this, systems are trained to maintain a consistent “character,” for example that of a helpful, honest, and harmless assistant, even during multi-stage conversations involving tens of thousands of tokens.
In parallel, mechanisms enhancing operational transparency are advancing. Modern models can not only refuse to fulfill a request but also explain the reason behind the refusal, for example, by stating: “I cannot fulfill this request because it violates principle X.” This introduces an element of accountability and strengthens user trust. Techniques like interpretable chain-of-thought are emerging, where the LLM generates an intermediate reasoning process that is subsequently verified by a separate “critical” component, improving the factual and ethical alignment of responses.
Industry standards and regulations increasingly influence alignment as well. Major model providers, such as OpenAI, Anthropic, Google, and Meta, commit to safety testing their systems before public release. Implementations include marking AI-generated content, an “off-switch” for autonomous agents, and systems for auditing generated responses. Alignment thus evolves from purely technical to a response to rising social expectations and regulatory requirements, particularly in regulated sectors.
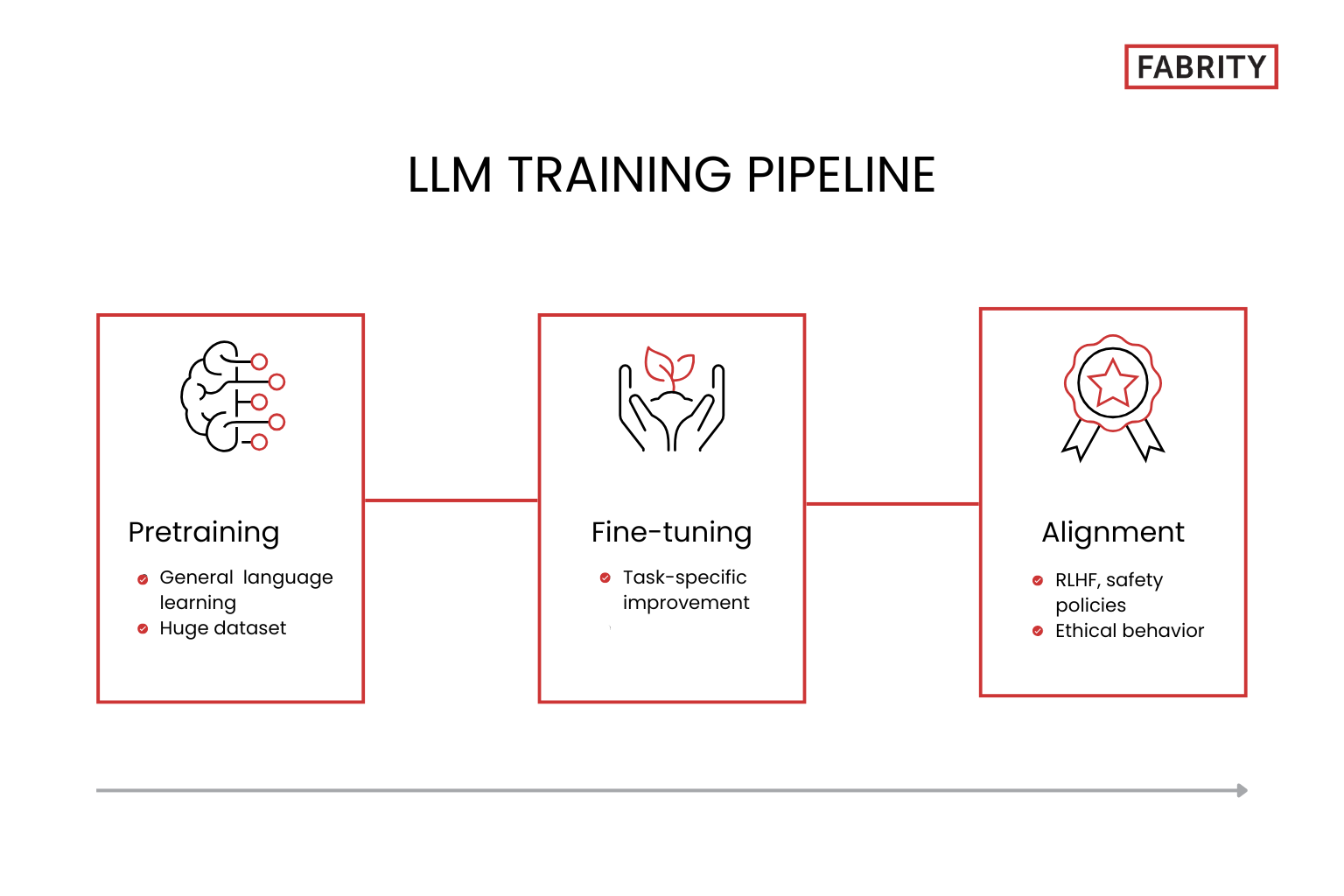
Fig. 1 LLM training pipeline
Prompt engineering
One of the most practical and dynamically evolving methods of utilizing LLMs is prompt engineering, also known as in-context learning. This approach involves constructing input queries containing instructions or examples that allow the model to generate the desired result without additional training or internal parameter adjustments.
In practice, various prompting techniques are used today depending on task type and the desired level of model control:
- Instruction-style prompts clearly state a command; e.g., “Translate this text into French” or “Generate a formal-style email.”
- Few-shot prompts provide several examples of correct queries and responses, allowing the model to grasp task structure without full training datasets.
- Chain-of-thought prompting encourages the model to reason step-by-step, significantly improving answer accuracy for tasks requiring logical reasoning.
- Tool prompts instruct the model when and how to utilize external resources, such as calculators, APIs, or file systems.
Dynamic prompts, generated automatically in real-time by intermediary systems, are also increasingly common. These solutions, sometimes termed LLM-as-router, analyze user intent, conversation history, and available knowledge sources to construct the most appropriate query on the fly.
Thus, prompts have evolved from mere instructions into powerful tools for controlling model behavior. Users can activate various operational modes such as “legal assistant,” “text editor,” or “coding mentor,” bringing LLMs closer to the concept of personal agents. Models adapt style, language, and the granularity of their responses according to the assumed role, all without any changes to their internal architecture.
With growth in the length and complexity of prompts, the need for their automatic optimization also grows. Specialized libraries and tools, such as Guidance, DSPy, and PromptLayer, have emerged to facilitate prompt construction, testing, and versioning, similar to the process followed for source code. This marks another step toward the professionalization of LLM utilization, increasingly resembling traditional software engineering practices.
What can large language models do?
LLMs didn’t just gain popularity for their uncanny ability to generate human-like text—they’re prized for their incredible flexibility. Capable of handling tasks ranging from the straightforward to those demanding sophisticated reasoning, these models have opened entirely new application areas. Here are their key capabilities:
- Text generation: producing coherent, logical, context-aware text from prompts, including articles, stories, summaries, product descriptions, and marketing messages.
- Code generation: recognizing programming patterns, suggesting syntax, and writing source code, making them indispensable aids to developers.
- Summarization: condensing lengthy documents, articles, or reports into brief, factual summaries.
- Language translation: translating texts across multiple languages while preserving context and register.
- Question answering: providing precise answers based on context; highly useful in education, documentation, and customer support.
- Conversational AI: conducting natural dialogues, responding in real-time, and maintaining conversational context, as seen in chatbots and virtual assistants.
- Information retrieval: extracting and presenting information clearly, exemplified by services like Bing’s Copilot and Google Chrome’s AI Overviews.
- Sentiment analysis: identifying emotional undertones (positive, negative, neutral) in communications, crucial for customer feedback analysis.
- Text classification: categorizing content thematically, formally, or semantically, useful for spam detection, tone labeling, and topic classification.
What can large language models do?

Text generation

Code generation

Summarization

Language translation

Question answering

Conversational AI

Information retrieval

Sentiment analysis

Text classification
Fig. 2. The LLM capabilities
How businesses use large language models
Due to their versatility and natural language understanding, LLMs are transforming industries from customer support to content creation, IT automation, and analytical decision-making, streamlining daily operations in virtually every sector.
Customer service and internal support are among the most common applications. LLM-based chatbots handle hundreds of queries daily, swiftly and accurately responding even to ambiguous requests. They manage everything from password resets to accessing company policies, assisting international organizations with onboarding, HR policies, and IT tickets.
Sentiment analysis and customer experience are also core use cases. E-commerce companies leverage AI to analyze customer emotions and opinions from emails, chat logs, or call transcripts. Models quickly pinpoint issues and assess service quality, enabling real-time adjustments and better customer experiences.
Organizational knowledge management has dramatically improved thanks to retrieval-augmented generation (RAG). LLMs swiftly search internal databases and documentation, instantly providing precise answers, saving employees from the need to perform manual searches and reducing risks from the use of outdated or missed information.
Content creation and marketing communications are thriving, with LLMs generating and editing diverse materials, from optimized blogs and social posts to product descriptions. Internally, these models refine reports, emails, and official documentation. CarMax, for instance, leveraged Azure OpenAI to auto-generate succinct vehicle descriptions, significantly enhancing customer satisfaction.
AI assistants in workplace tools became standard practice by 2025. Microsoft 365 Copilot integrates into Word, Excel, Outlook, and Teams, creating documents, analyzing data, and summarizing meetings. Google Workspace’s Duet AI offers document summaries, email generation, and spreadsheet automation, making these models full-fledged digital assistants, seamlessly operating within unified work environments.
IT automation and developer support see growing roles for LLMs. Tools like GitHub Copilot, Codeium, and Amazon CodeWhisperer suggest code, create unit tests, write documentation, and aid debugging. In DevOps environments, AI automates pipeline management, infrastructure oversight, anomaly detection, and security incident response.
Data analytics and decision-making have been transformed with natural language queries converted into SQL, delivering analytics accessible even to nonspecialists. Platforms like Microsoft Analyst Copilot in Power BI and Salesforce Tableau offer rapid, precise business insights, drastically accelerating decision-making processes.
Marketing and multimedia creation increasingly harness AI capabilities. Platforms such as HubSpot and Adobe Sensei automate content campaigns, from emails and product pages to graphics and blogs. Multimodal LLMs can simultaneously produce text and imagery, enabling cohesive, visually appealing communications. Media organizations use AI to summarize articles, analyze trends, and generate content concepts, with humans retaining final editorial oversight.
Challenges and limitations of large language models
Despite their impressive capabilities, LLMs pose notable challenges around response accuracy, safety, transparency, costs, and environmental impact.
The most prominent issue is hallucination, where models generate seemingly logical but false or inaccurate content, which is particularly problematic in regulated industries like law, medicine, and finance. To mitigate this, businesses increasingly use fine-tuning with verified datasets, RAG mechanisms, and hybrid architectures enabling real-time external fact verification.
Another major concern is information security and data privacy. Models accessible via APIs, if inadequately secured, pose threats to confidentiality, especially involving personal or financial data. In 2025, organizations commonly deploy models within isolated cloud environments like Microsoft Azure, Google Cloud Vertex AI, or Amazon Bedrock that offer encryption, access control, and regulatory compliance (GDPR, HIPAA). Alternatively, many companies opt for locally hosted open-source models to maintain tighter security controls.
Bias and prejudice embedded in training data (often Internet-derived) is another serious risk, potentially leading models to amplify stereotypes and misinformation. Strategies like quality filtering, debiasing techniques, and ongoing output monitoring have become crucial. Tools like constitutional-based alignment and model critics increasingly help organizations limit undesirable content and ensure models align with social and corporate values.
The fourth limitation is a lack of transparency, making LLMs essentially “black boxes.” Their reasoning, based on millions of connections, is challenging to track, posing significant issues for regulated sectors (finance, insurance, public administration). The field of explainable AI (XAI) is growing, with increased transparency through methods like chain-of-thought prompting, critique models, and faithfulness evaluation to provide justifications and data sourcing alongside outputs.
Last, there are rising concerns around costs, both financial and environmental. Training and operating large models require vast GPU resources, energy, and specialized cooling. Amid the climate crisis, more organizations are adopting sustainable alternatives like efficient fine-tuning (LoRA), quantization, pruning, and MoE architectures, activating only necessary parameters per query to conserve resources.
As an alternative, small language models (SLMs) with 1–10 billion parameters are gaining traction. Compact and efficient, they offer quick, affordable, and controllable local deployment ideal for edge devices, routers, smartphones, or offline systems, handling simpler queries, form analysis, or operational tasks.
These limitations highlight the need for responsible and mindful deployment, going beyond mere access to cutting-edge models to encompass powerful abilities, best practices, and clear technological and ethical frameworks.

The future of large language models
Today’s leading models—GPT-4o, Claude 3, Gemini 2.5 Pro, and Llama 4—handle not only text but also images, audio, and video. With multimodal capabilities and context lengths extending up to a million tokens, they effectively analyze complex data, conduct multilingual dialogues, and adapt dynamically to user roles, becoming increasingly powerful, cost-efficient, and finely tuned to diverse needs.
LLM architectures are evolving as well. Transformer dominance remains, but techniques like MoE, FlashAttention, LoRA, and RLAIF are increasingly mainstream, creating powerful yet energy-efficient models that are accessible even to smaller teams. The paradigm shift is clear: from “bigger is better” to “smarter is more efficient.”
LLMs are no longer experiments—they’re integral tools powering office suites, BI platforms, CRMs, chatbots, DevOps, automated workflows, and specialized assistants for sectors like law, medicine, accounting, and sales. Businesses are mastering not only model use but also training, monitoring, and integration into their internal systems.
At the same time, awareness of their limitations (hallucinations, biases, transparency gaps, data leaks, and high computational costs) is growing. Organizations increasingly set internal AI policies, adopt locally hosted open-source models, and invest in explainable AI and alignment technologies.
Emerging trends like multimodality and agentive functionality now define future paths. Models are no longer restricted to text comprehension—they interpret charts, process visual inputs, listen, and execute user commands. Direct integration with external tools (APIs, files, email) paves the way toward true AI agents performing tasks on users’ behalf.
Finally, openness and democratization continue expanding. Meta, Mistral, Hugging Face, and others provide increasingly powerful open-source models, democratizing AI access for startups, SMEs, and public institutions, fostering a healthier innovation ecosystem.
Simultaneously, safety and ethics grow paramount. Challenges like deepfakes, prompt injection, and data leaks are real concerns, spurring regulatory frameworks (such as the EU AI Act), detection technologies, and research initiatives focused on safe AI development, with superalignment efforts leading the charge.
This article was originally published on May 20th, 2024, and updated on June 2nd, 2025.






