

Azure Pipelines is a tool included among the Azure DevOps services (once known as Team Foundation Server). Like any pipeline tool, it’s a way for software development teams to plan out the various workflows and processes. That way, there’s more consistency among all the engineers working on a software project, which improves the reliability of the final product. This article will explain why developers use Azure Pipelines.
Continuous integration and continuous delivery
Continuous integration and continuous delivery are terms referring to how software—especially mobile and web apps—are updated, made possible by today’s always-on, always-connected digital lifestyle.
Continuous integration (CI) is how multiple developers can make changes to an app’s code, which are then automatically merged and tested. This allows bugs to be caught at an early stage of the development cycle so that fixing the code is less time-consuming.
Continuous delivery (CD) means just what it says: as soon as the build is done and passes testing, it is manually deployed. CD can also refer to continuous deployment, in which the deployment is automatic.
Azure Pipelines, a Microsoft product you would naturally use for an Azure DevOps project, is a tool that manages these CI/CD processes, i.e., compilation, testing, code merge, and implementation. The intent behind its design is to eliminate human involvement to the greatest extent possible—especially eliminating the need for different people to be involved during the various stages, thereby reducing the risk of errors due to communication problems.
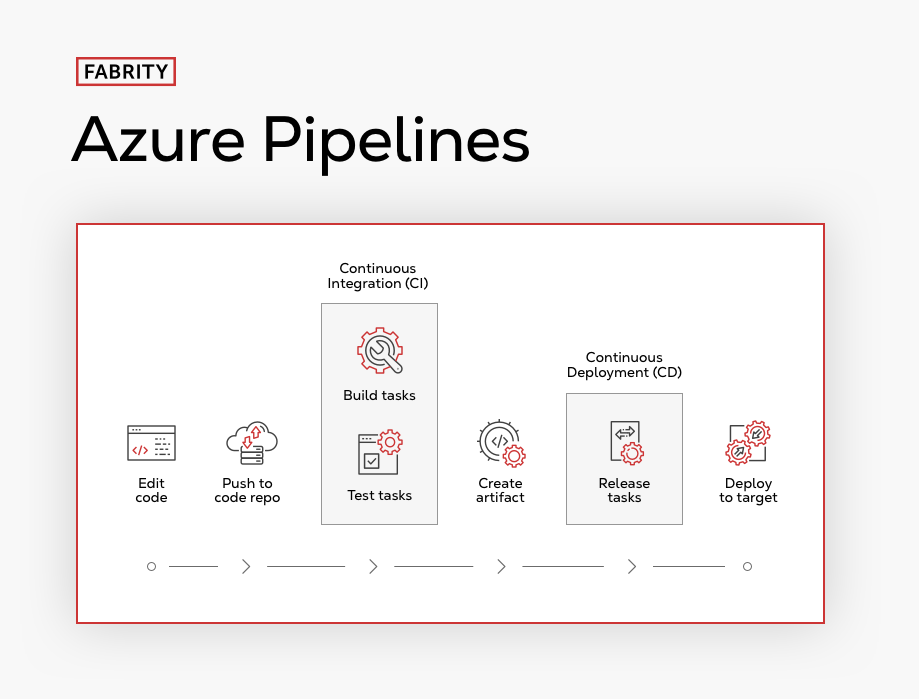
Fig. 1 CI/CD process overview
However, despite belonging to the suite of Azure services, Azure Pipelines supports more than just Windows-related architectures (.NET, Universal Windows Platform, and C++).

Fig 2. Azure Pipelines—supported technologies
It can also be used to build Android, iOS, JavaScript, and Java applications. Deployment targets include:
- the Azure platform
- Windows virtual machines
- Linux virtual machines
- Kubernetes
- NuGet
- NPM

Fig 3. Azure Pipelines—supported platforms
Naturally, Azure Pipelines supports Azure Repos GIT and Azure Repos Team Foundation Version Control (TFVC). But we’re also given a choice of GitHub and GitHub Enterprise Server, Subversion, both the Cloud and Server versions of Bitbucket, and more.

Fig 4. Azure Pipelines—supported repositories
Building a pipeline in Azure Pipelines
Azure Pipelines gives us two ways to build and deploy.
- We can use a visual editor. Individual tasks are dragged to the pipeline and then configured. This is a standard method that is available for all types of projects.
- For Azure Git, GitHub, and Bitbucket projects, we can use a pipe definition in a YAML file. We can edit it in Azure DevOps, or we can use any text editor. Then we commit this file to a repository such as a Git repository.
In much the same way as any physical production pipeline, a CI/CD pipeline such as Azure Pipelines has stages. Typically, these are:
- Build (compiling the code)
- Test (usually automated checking of the code for typos and bad syntax)
- Release (not to the public, but to a repository)
- Deploy (the code goes to production environments)
- Validate (checking that all of the graphics and text are correct and meet company or client standards)
It’s really only after the validation stage that the CI/CD magic happens.
So, first we need to select which environment we are building in and targeting our deployment. That’s how the pipeline will know how to test the build as you go. The deployment targets are those listed above.
Next, we define the triggers. What action will cause the Azure Pipelines to run a test? When, and how often should it run? The following are the available choices:
- CI-triggers will run the pipeline as soon as the code on the connected branch is updated.
- PR-triggers will run the pipeline when a pull request is created on an attached branch or when new changes are posted.
- Scheduled triggers.
- Pipeline triggers will run when another pipeline finishes.
- Comment triggers, available only for GitHub, will run when a specific comment is entered in a pull request.
Then comes the simple step of specifying which version of the software Azure Pipelines will be used via the version control system.
The task list
Now that the specifications are made, we can choose the tasks. There’s plenty to choose from, and yet, if there’s a tool elsewhere that you find useful, you can install it too. There’s even an option of whether to use Azure DevOps to build and deploy or the older but still useful Jenkins.
If your project is intended for multiple targets (platforms), you’ll want to use cross-platform scripts. Even though each script may do certain things differently (such as handling variables), Azure Pipelines has an option to write your way around these obstacles, with a syntax that is essentially unwrapped uniquely, specific to each platform.
The available tasks are categorized as follows:
- Build
- Utility—these are a variety of tasks, from archiving to decrypting to copying or deleting, and more.
- Test
- Package—these tasks involve authenticating, opening build environments, and publishing.
- Deploy—define your deployment targets with these tasks.
- Tool—mostly installers, and some tasks for choosing the proper version of coding language.
As you can see, some of these tool categories match the pipeline stages listed above.
When you use Azure Pipelines, you are given various options in terms of controlling the tasks you set. You may decide to set the condition that a task should only run if previous agent runs (sets of tasks) have succeeded, or only if a previous run failed, or it should simply run regardless of the result of previous runs.
You may also decide to let the task run again if the previous run failed and define how many times it tries again.
Finally, there is the option of defining or adding in custom tasks from outside the Azure Pipelines provided list and Marketplace.
Another feature of the pipeline is branching, for adding new features. When compiled, the pipeline will test the code for that feature against the rest of the code to identify any compliance problems.
Will it work?
Speaking of testing, there are some interesting options to consider; the pipeline can run tests that you’ve added to the repository, and it can run user interface tests. It can run tests on multiple agents simultaneously—up to 99 at a time. Each separate branch is known as a job.
Furthermore, Azure Pipelines lets you choose either agents which are hosted—and maintained—by Microsoft or agents installed on your own system. (These of course will require your own time and effort to maintain, but it does make for a faster testing process.)
The test results are saved in the build summary as a simple report. A team member can then analyze any errors that may have turned up.
Once the code passes all of the tests, the pipeline builds what’s called an artifact. This artifact is what will be pushed out for implementation in the app as an update. We could choose to make Azure Pipelines handle implementation automatically, make it wait for approval, or make implementation manual.
No need to reinvent the wheel
As you’ll have noticed, Azure DevOps services is full of provided tools, some from within Microsoft and some from without. Once you’ve created anything with your pipeline, whether a task, a job, or indeed the entire pipeline, you can save your work as a template for others to use in the future. Your colleagues and your future self will thank you!
Wrapping up
It would be somewhat trite to describe the process of building an Azure pipeline as easy, but Microsoft has put a great amount of effort into making CI/CD accessible for more developers while also reducing the risk of errors and project delays. By enabling the five typical stages, and more, and by providing their own tools while leaving the door open to outside tools, they’ve given Azure DevOps as a whole a really strong use case.
We wish you luck with your next pipeline project!






