

ChatGPT, despite all its undeniable capabilities, has one serious flaw—it hallucinates answers. Fortunately, there is a solution to this daunting problem, called the RAG system. It allows you to ensure that the answer given is correct and based on up-to-date information, while harnessing the power of large language models. In this article, I will explain what RAG is and how it can be applied in business scenarios.
What is retrieval augmented generation (RAG)?
A retrieval augmented generation mechanism is an approach in machine learning that enriches the capabilities of large language models (LLMs) by dynamically integrating external data during the text-generation process. It operates through two main components:
Retrieval System: this system utilizes a neural network that encodes both the query and the documents into a dense vector space. When a query is made, the model retrieves the most relevant documents from a large-scale database (for example, a company’s knowledge base), treating it as a specialized corpus. This process is guided by the similarity between the encoded vectors of the query and the documents.
Sequence-to-sequence model: the retrieved documents are then concatenated with the query to serve as an extended input for the sequence-to-sequence model. This model, which often has a transformer-based architecture, generates the output text. It uses the context provided by the retrieved documents to make the generated text more accurate, relevant, and informationally rich.
Integrating RAG with LLMs allows the models to not only rely on their pretrained knowledge but also to access and incorporate real-time, context-specific information from external sources. This makes the LLMs more effective for tasks requiring up-to-date knowledge or specialized information that is not covered in their training data. In other words, with RAG you can build a system to which you can upload large sets of documents and ask natural-language questions about their content. In this way, you can search large, dispersed sets of data to find precise answers to your queries, including very complex ones.
What tasks retrieval augmented generation can perform
Retrieval augmented generation technology can enhance various operations, including:
- Question answering: RAG can enhance question-answering systems by retrieving relevant information from a database before generating an answer, leading to more accurate and contextually appropriate responses.
- Information retrieval: This is a fundamental function of RAG, as it involves searching the database to fetch relevant data or documents based on a query, which is essential for the subsequent generation tasks.
- Document classification: While RAG primarily focuses on generating responses from retrieved data, it can assist in document classification by providing enriched context that helps in categorizing documents more accurately.
- Information summarization: RAG can effectively summarize content by first retrieving relevant information from a larger dataset and then synthesizing that information into a concise summary.
- Text completion: RAG can be used to complete text by retrieving contextual information from related texts, thereby enhancing the relevance and accuracy of the completed text.
- Recommendation: In the context of RAG, recommendations can be made more relevant by using the retrieved information to provide suggestions that are tailored to the user’s current context or query.
- Fact-checking: RAG can aid in fact-checking by retrieving evidence from a trusted database to confirm or refute claims made in text, enhancing the credibility of the generated content.
- Conversational agents: For chatbots or virtual assistants, RAG helps create more informed and accurate responses by leveraging both the immediate query and additional context from related data sources.
How retrieval augmented generation works
In RAG, you provide relevant context to the LLM by adding it to the prompt. This process raises the question of how to identify this context. Here comes a less well-known child of the AI revolution: the embeddings model. This model transforms text into a vector within a high-dimensional space. Texts that share meanings have similar vector representations, while unrelated texts differ significantly. The similarities between vectors allow us to determine which texts are most relevant to each other. These embeddings are stored in vector databases that can be seen as the heart of a RAG system.
Now, we can show how the RAG process runs:
- The user’s query or prompt is passed to the RAG model.
- The RAG model encodes the query into text embeddings (numeric representations of the meaning of the text).
- The encoded query is compared to a vector database of embeddings created from external data sources (e.g., technical documents, knowledge bases, FAQs, company procedures, product sheets).
- The retriever module in the RAG model identifies the most relevant information based on the semantic similarity between the query and the vector database of embeddings.
- The retrieved information is passed to the generator module along with the original query.
- The generator combines the retrieved information with the query and passes it through the LLM to generate a natural-language response.
- The LLM produces the final answer, potentially citing the relevant sources retrieved in the previous steps.
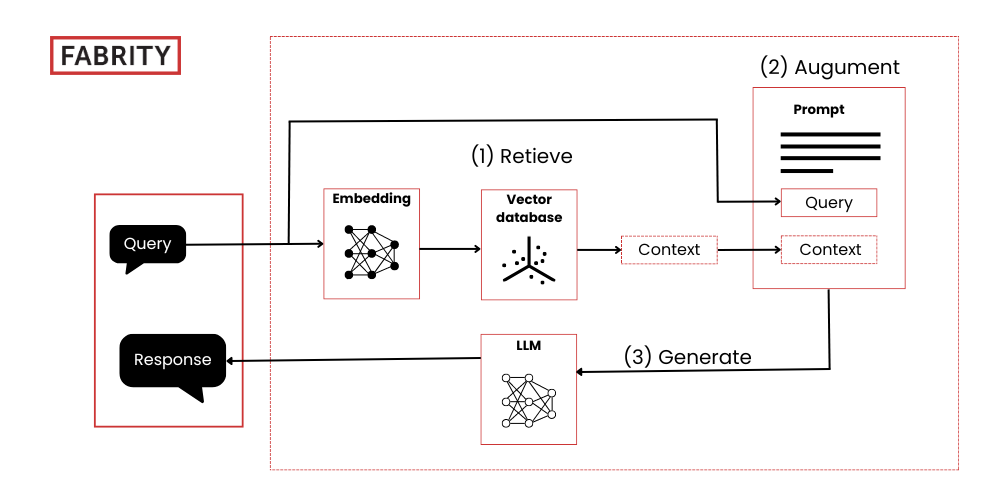
Fig. 1 How retrieval augmented generation works (source)
What are benefits of retrieval augmented generation?
Retrieval augmented generation offers several compelling benefits that enhance the functionality and reliability of AI-driven applications.
No hallucinations
Since the answers it gives are grounded in verified knowledge, a RAG mechanism removes the daunting problem of the hallucinations produced by ChatGPT or similar generative AI models. Chatbots based on LLMs tend to hallucinate answers because they try to give the most probable answer based on the data used to train the model. If the precise answer is not in the model’s data, it gives its best guess, which is not necessarily correct. In contrast, the RAG mechanism looks for answers in the dataset provided, while an LLM is used only to generate the answer. In other words, RAG is not limited to the data used for model training but can retrieve information from external knowledge databases.
No training needed
Although fine-tuning an LLM, i.e., adjusting it to a specific domain, is possible and can bring good results, it is a process that requires specialized knowledge, as well as lots of training data and computational resources. Additionally, this fine-tuning should be repeated if new knowledge appears. With RAG you do not need to do this, and the process of data indexation is much more straightforward.
Citing information sources
LLMs are blackboxes that generate answers in ways we cannot see or control. In contrast, using RAG mechanisms we can check how answers are generated, i.e., based on which sources. This feature means a lot in business contexts, such as customer service or technical maintenance, where precise and correct information is what matters the most.
Covering domain-specific topics
LLMs, despite their immense capabilities and extensive knowledge, can struggle with complex queries that require more in-depth, specialized knowledge. Retrieval augmented generation addresses this issue by allowing you to integrate specialized knowledge into a GPT-powered chatbot to obtain precise answers. This integration is particularly crucial in domains such as the legal, technical, or financial sectors, where the accuracy of responses is critical.
Dynamic content integration
All large language models are trained on data from up to a certain date in the past. ChatGPT 3.5., for instance, was trained on data up to September 2021. This means that the model may not reflect more recent information or changes. To include changes, retraining is necessary, which takes time and requires lots of computational resources.
The RAG mechanism allows for constant updates with the latest data without the need for repeated retraining. To update the knowledge that the model accesses, simply replace the documents in the vector database. This process eliminates the need for additional steps, ensuring the model remains current with minimal effort. This is particularly valuable in rapidly changing fields such as customer service or manufacturing.
Data confidentiality and security
The dataset from which the RAG model retrieves information is separate from the training data of an LLM. It is not used to retrain an AI model and can be securely stored within the Azure infrastructure to ensure enterprise-grade security.
Read more on new disruptive technologies:
Generative AI in knowledge management—a practical solution for enterprises
Is ChatGPT dreaming of conquering the world? Generative AI in business
The power of generative AI at your fingertips—Azure OpenAI Service
Unleash your superpowers with new Power Platform AI capabilities
How to build a blockchain app for tracking of manufactured parts
Blockchain for business—a gentle introduction
Is blockchain in supply chain management a real disruption or just hype?
Business process optimization in the pharmaceutical industry in 2024—7 practical use cases
Business use cases for retrieval augmented generation
The RAG mechanism can be applied in many business scenarios. Let us examine them in detail.
RAG in customer support
RAG can enhance the capabilities of chatbots and virtual assistants by retrieving relevant information from a company’s knowledge base, including FAQs, product specifications, troubleshooting guides, and user manuals. When a customer poses a question, the chatbot leverages both the query and the retrieved knowledge to generate responses. This allows a customer support agent to respond quickly and precisely to customer queries.
Additionally, the RAG mechanism can enhance self-service options for customers. A chatbot can access customer data and do typical tasks (e.g., a password change, adding a new shipping address, changing the payment method, updating account information, and many more).
RAG in retail: product query chatbot
Utilizing RAG, retailers can build a product query chatbot capable of fetching specific product details from vast databases in near-real time. This enhances the responsiveness and accuracy of customer queries. Not only does this streamline customer support, but it also ensures that precise product information is relayed, leading to improved customer satisfaction and shopping experiences.
Consider such a use case: an online electronics retailer with thousands of products listed. A customer might ask a chatbot about the best mobile phone and get precise advice based on product data. The integration of a chatbot with the customer’s account would allow the customer to order the phone by choosing shipping and payment methods. Everything could be done via a single chatbot interface.
RAG in retail: customer feedback analysis
RAG processes deep insights from comments, reviews, and ratings, creating comprehensive reports that pinpoint customer preferences and pain points. Armed with this data, retailers can refine their products, services, and strategies to better meet customer needs, enhancing the overall shopping experience.
Consider such a use case: an online store debuting a new product line. Using RAG, the store aggregates and analyzes feedback across different platforms to discern customer sentiments. It identifies recurring issues or praise related to specific features. The store then addresses these concerns or leverages positive feedback, improving customer satisfaction and potentially boosting sales.
RAG in retail: personalized product recommendations
RAG leverages customer data such as past purchases and browsing history to personalize product recommendations in real time, aligning suggestions with individual user preferences. This dynamic approach leads to enhanced user engagement, longer browsing sessions, and higher conversion rates, thanks to RAG’s rapid data processing and response capabilities.
Imagine an online gourmet coffee retailer. A user who previously purchased espresso beans logs in after several months. Using RAG’s capabilities, the site analyzes past purchases and browsing history to dynamically suggest a new batch of similar beans or a premium coffee grinder that enhances the customer’s brewing setup. These tailored recommendations improve the shopping experience, encouraging further exploration and increasing sales.
RAG in supply chain: streamlining B2B sales
In the B2B sales process, responding to requests for proposals (RFPs) or requests for information (RFIs) is often time-consuming. By using RAG, companies can streamline this task by automatically filling out these forms with relevant product details, pricing, and previous responses. RAG enhances the accuracy, consistency, and speed of generating these responses, thereby simplifying the sales process, minimizing manual labor, and increasing the likelihood of winning bids by quickly meeting client needs.
Of course, a RAG-based solution needs to be integrated with external systems, like CRMs or product information management (PIM), to fetch product and client data.
Imagine a huge B2B company selling technical equipment. Every RFP or RFI is prepared by a sales specialist, which means that only the biggest customer gets it on time—the smaller ones need to wait in a long queue for their turn. Because of that, the company loses a considerable revenue stream. A RAG-powered solution could automate the process of responding to RFPs/RFIs so that every potential customer gets one in time, regardless of the size of their company.
RAG in supply chain: choosing the best supplier
For effective procurement strategies, precise recommendations are crucial. RAG enables organizations to automate procurement recommendations by analyzing historical purchasing patterns, vendor performance, and market trends. These insights help ensure optimal supplier selection, cost savings, and risk reduction, paving the way for strategic purchasing and enhanced vendor relationships.
A large manufacturing company utilizes RAG to refine its raw material sourcing strategy. By analyzing extensive procurement data, RAG identifies suppliers that consistently adhere to quality standards, deliver on time, and provide competitive pricing. This allows the manufacturer to prioritize relationships with top-performing vendors and negotiate more favorable terms. This strategy helps the manufacturer secure a reliable supply of high-quality raw materials, minimize production delays, and improve overall supply chain efficiency.
RAG in finance: ensuring compliance
RAG’s capabilities for fact verification and compliance validation are invaluable in the legal and compliance sectors. When handling legal documents or meeting regulatory demands, RAG can cross-reference data from reliable sources to ensure the creation of legally accurate documents. Its robust fact-checking ensures that all information complies with legal standards, reducing the risk of errors and boosting overall compliance.
Imagine a financial services company that needs to adhere to stringent anti-money laundering (AML) regulations. Using RAG, the company can automatically cross-check customer transactions against global watchlists and historical data in real time. Before processing significant transactions, RAG verifies their legitimacy against current AML standards and automatically flags any suspicious activities. This process not only minimizes the risk of legal penalties but also expedites transaction processing, reduces operational costs, and maintains the company’s integrity in the financial market.
RAG in insurance: insurance claims processing
RAG allows for automatic insurance claims processing. This process often requires navigating through extensive documentation. By deploying RAG, insurers can swiftly access relevant policy details, claims histories, and regulatory guidelines. RAG facilitates generating preliminary assessments, detecting potential fraud based on historical data, and auto-filling forms with necessary details. This automation streamlines the claims approval process, enhances accuracy, and ensures consistency.
Consider a car insurance company inundated with claims after events like storms or floods. Manual processing is slow and error prone. Implementing RAG, the insurer’s system instantly retrieves policy details and historical data as soon as a claim is submitted, compares it with previous claims, and provides a tentative evaluation based on policy guidelines. This rapid processing speeds up claims handling and significantly improves customer experience during stressful postaccident scenarios.

RAG in manufacturing: streamlining machinery maintenance
Retrieval augmented generation enhances machinery maintenance in manufacturing by delivering timely, pertinent information to maintenance teams. RAG-powered chatbots can provide maintenance technicians instant access to machine manuals, troubleshooting guides, and repair histories, assisting in diagnosing and resolving issues swiftly. By leveraging sensor data and maintenance logs, RAG can also facilitate predictive maintenance models that anticipate machinery failures, enriching these predictions with real-time sensor readings and historical data for higher accuracy.
Additionally, RAG can automate spare parts ordering and optimize maintenance scheduling by integrating with ERP and CMMS systems, allowing for maintenance activities to be planned according to real-time equipment status and technician availability. This integration not only streamlines processes but also minimizes downtime and maintenance costs, enhancing overall equipment efficiency and product quality.
Imagine a large automotive manufacturer that integrates RAG with its existing CMMS to develop an intelligent maintenance system. When a crucial production line machine begins showing early signs of wear, the RAG system automatically analyzes the machine’s sensor data against historical maintenance logs and predicts a potential breakdown. It then proactively schedules maintenance during planned downtime, orders the necessary spare parts, and prepares detailed maintenance instructions. This strategic approach minimizes downtime, reduces maintenance costs, and ensures that the production line runs smoothly, ultimately leading to improved reliability and quality in vehicle production.
RAG in streamlining day-to-day operations
Since retrieval augmented generation allows for efficient information retrieval, it can be integrated with a GPT-powered chatbot to build a virtual assistant that helps employees to effectively search the company’s knowledge bases or to perform various tasks.
Imagine an HR chatbot that provides employees with instant access to company policies, benefits information, and HR-related FAQs. It’s also a significant help for newcomers that need to orient themselves in a sea of company regulations. Additionally, the chatbot allows them to streamline tasks such as leave scheduling or compensation and benefit management.
Another use case is an AI-powered IT support system, where employees can get instant access to all troubleshooting guides and how-tos, as well as perform some actions (like changing password, ordering new equipment, etc.) by themselves without bothering the IT support team.
In sales and marketing teams, retrieval augmented generation allows users to generate personalized sales and marketing content like email templates, social media posts, and product descriptions by retrieving relevant customer data, industry trends, and brand guidelines.
Retrieval augmented generation in practice: integrations
The effectiveness of retrieval augmented generation (RAG) hinges on its integration with other company tools and software. While RAG can address numerous business challenges, it cannot operate in isolation. A successful RAG system requires an ecosystem comprising various components, including a large language model (LLM) such as GPT or an open-source alternative, external data sources, and integration with the company’s communication tools, such as Teams or Slack. Additionally, connections with CRM, ERP, or PIM systems are essential. It is crucial to understand that no mechanism, regardless of its efficacy, will function effectively unless it is part of a larger ecosystem.
Applying RAG to your business use case
If you have reached thus far reading this article, you might wonder how RAG can help in your business case. You can give it a try, and we can help you with that by building a dedicated demo of our knowledge management solution that combines the power of LLMs with retrieval augmented generation. The process runs as follows:
- We analyze potential use cases, such as technical documentation, internal knowledge bases, customer support, product catalogs, and more.
- We gather the source documents needed for the project.
- We set up the necessary Azure infrastructure to support the solution.
- We train the solution using your documentation to ensure it meets your specific needs.
- We test and optimize the solution to maximize its effectiveness and efficiency.
Once you gather the training data, the entire process to construct a customized demo of an AI-powered knowledge management solution will take approximately 2 to 3 weeks.
Please email us at sales@fabrity.pl, and we will reach out to discuss all the specifics with you.
You can also read an article on how we built an AI-powered knowledge management solution for enterprises.






