

Artificial intelligence is desirable for at least two important reasons: reducing errors and freeing human intelligence from repetitive, time-consuming tasks. Until fairly recently, however, AI tools have required bespoke development by computer science specialists, keeping the implementation of most potential applications cost-prohibitive. AI Builder, a component of Microsoft Power Platform, allows citizen developers to use AI technology to significantly facilitate and organize some of the processes taking place in enterprises. Let’s have a closer look.
The AI Builder component
Based on Azure AI Cognitive Service, AI Builder is a tool for creating and training models without writing code. Integration with Power Apps and Power Automate is a built-in feature, providing users with the opportunity to extend and improve existing business applications. Microsoft has also compiled (pre-built) models for typical business scenarios which a user can implement as-is in other platform services or refine and train (customize) the models according to various business needs and goals (see Fig. 1):


Fig. 1 AI models based on Azure Cognitive Services
Microsoft doesn’t license AI Builder separately but rather as an add-on to an existing Microsoft license, be it Power Apps, Power Automate, or Dynamics 365. If the license you have entitles you to create a Dataverse database, you have the option of using AI Builder on a trial basis. Even if you don’t, you may already have some AI Builder capabilities in the Power Platform components you use. Ask your environment admin to check and add one or several AI Builder capacity add-on units if needed.
Read more on low-code development:
Unleash your superpowers with new Power Platform AI capabilities
Is low-code development a panacea for the tech talent shortage in 2023
Hyperautomation—an emerging technology trend for 2023
Power Automate flow with Teams: how to optimize the approval process
How to build a customer service chatbot with Microsoft Power Virtual Agents
Low-code app development—a trend for 2022
Digital process automation with low-code platforms—5 typical use cases
Microsoft’s Power Virtual Agents: for highly capable chatbots
How you can streamline your business process with Power Automate
What is Microsoft Power Platform—an overview of the main features
AI Builder–custom models
The first decision in building a model is to determine whether business requirements call for ready-made, compiled patterns or training one of the models provided. In the second case, there are five custom models to choose from on their intuitive interface (see Fig. 2):
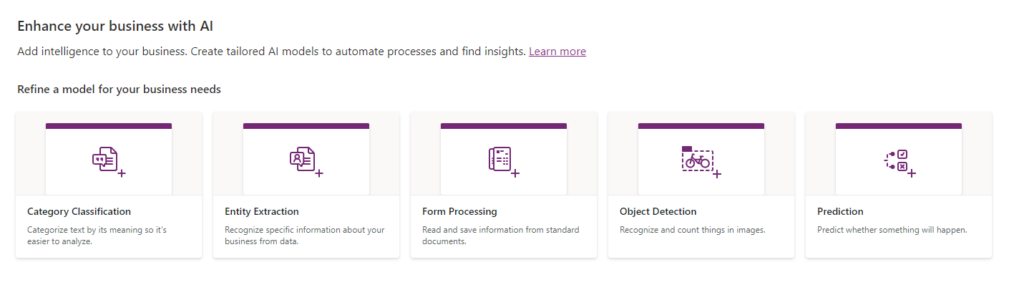
Fig. 2 AI Builder custom models
Category classification is intended to analyze large volumes of text data—documents, social media entries, e-mails, etc.—and classify the text to, for example, detect spam or correctly direct customer inquiries to an online store. The model must be trained with data in Dataverse, with the text and tags organized into two columns on the same table. Up to 200 different categories—tags—can be defined. The languages currently supported include English, French, German, Italian, Spanish and Portuguese. The character limit for each data sample is 5,000 characters.
Upon creating a Category Classification model, AI Builder will offer examples (see Fig. 3):
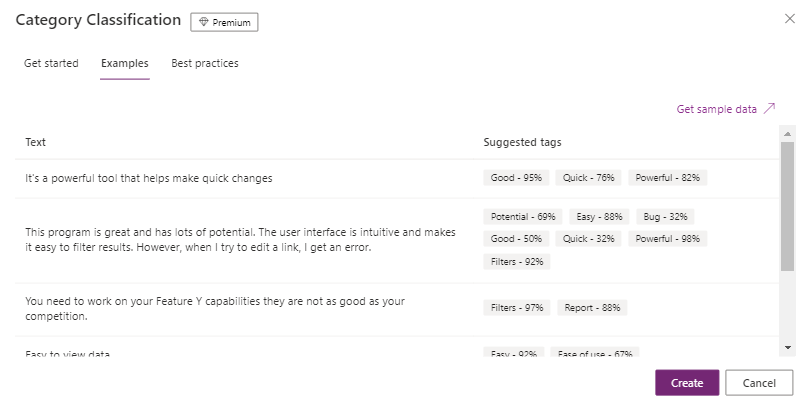
Fig. 3 AI model: Category Classification
The analyses these models provide will free up time for employees to take relevant action and can also be used as input for other AI features, from predictive analytics to unsubscribing a user. It is important that the model be fed with at least ten text samples per tag to be extracted. Otherwise, the model’s predictions are less likely to be correct.
Entity Extraction (preview version) identifies key text elements and assigns them to defined categories. This standardizes and structures the results appropriate to our business needs. The data will also be more machine-processable and available for use in other applications. Currently supported languages include English, French, German, Portuguese, Italian, Spanish and Chinese (simplified). See Fig. 4:
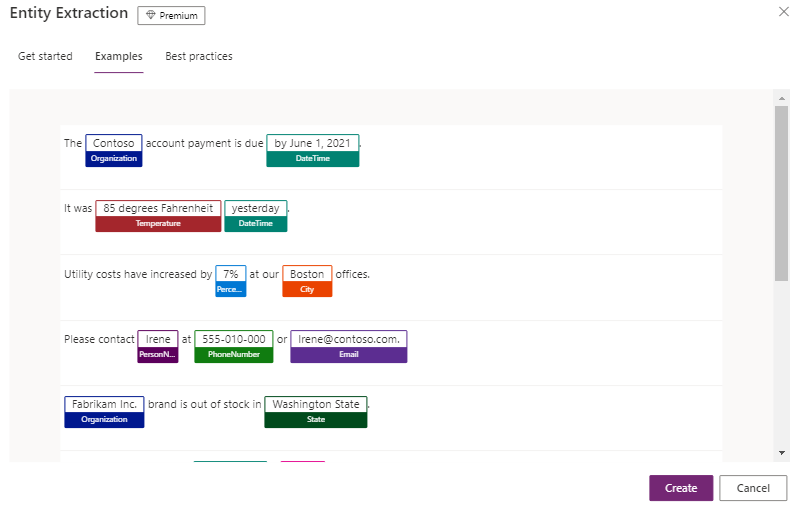
Fig. 4 AI model: Entity Extraction
At least 10 data examples are needed to begin training the model. It isn’t necessary to find that much data—you can customize the model by creating new entity types with a small set of examples or modifying existing entity types. That is to say, AI Builder has pre-built data tables which can be used to augment your training data.
Form Processing is the AI model which extracts data from forms, even paper or PDF documents. It quickly imports data into tables in the Dataverse database. As few as five example forms are enough to train this model to map the fields in a document and create a working application. This solution is ideal for quickly entering invoices, orders, complaints, sales bills, insurance documents, applications, and so on. It is possible, for example, to train the model and create a flow that will automatically recognize and extract key information from order documents received in PDF e-mail attachments. After extracting this information, the form processing model will save it in the order table and send the appropriate notification to the Customer Service Department (see Fig. 5).
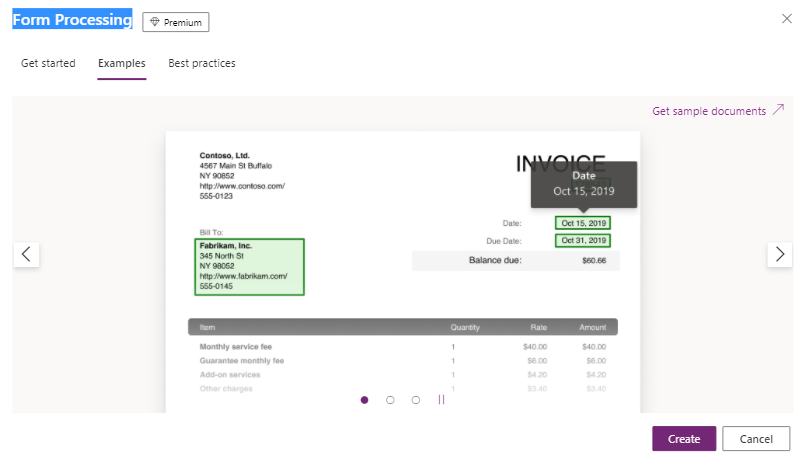
Fig. 5 AI model: Form Processing
The recommended formats for input data are .jpg, .png, and .pdf. The total size of the documents used for training must not collectively exceed 50 MB. The file dimensions must be at least 50 x 50 and no more than 10,000 x 10,000 pixels; for PDF files, the maximum dimension is 17 x 17 inches. Only English is currently supported.
Object Detection can detect objects seen in photos. Training this model naturally means providing AI Builder with photos and the names of the objects to be learned. This mechanism can be used to identify products, machines on the production line, barcodes, etc. It’s a handy tool for field employees, who can run an artificial intelligence-powered mobile application to identify an object and receive up-to-date information about it—product descriptions, operation manuals, or inventory counts. At least 15 photos of each object are needed for training; the more photos, the more accurate the model. Photos should include a variety of backgrounds with the featured objects at different distances and angles to help improve correct object identification (see Fig. 6).
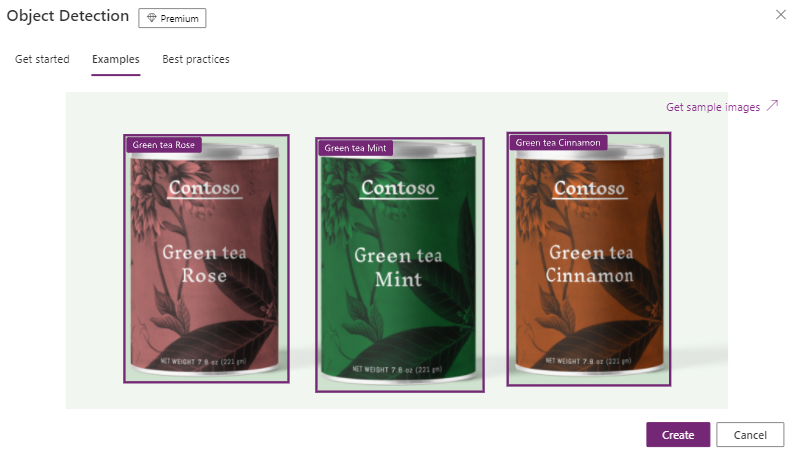
Fig. 6 AI model: Object Detection
It should be noted that the training images must be in .jpg, .bmp or png format and cannot collectively exceed 6MB per training, though the photos must not be less than 256 by 256 pixels. More consistent results are possible when the ratio between the objects with the fewest and most images is at least 1:2. To put that another way, if 500 is the highest number of training images for one object, then there must be at least 250 training images for the object with the fewest.
Prediction is a model which analyzes large amounts of historical data to discover patterns and link those patterns to the results. This knowledge is then used to detect the patterns in new data—to predict future events. These mechanisms can reveal patterns that answer binary (yes/no) questions, questions with multiple answers (a list of results), or questions answered with a number. For example, Will the customer buy the product? (yes / no); Will the customer pay invoices on time? (yes / no); Which products might interest the customer? (list); How many items of a particular product should we keep in stock? (number). See Fig. 7:
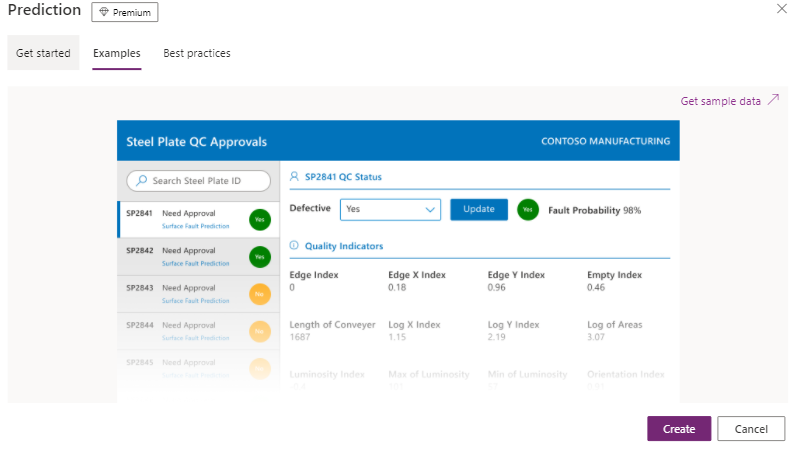

AI Builder pre-built models
Rather than collecting large amounts of data to create, train, and publish bespoke models, these pre-built components make adding artificial intelligence to our applications and automated workflows quicker and easier. The ready-made templates are available for use in the Power Apps mobile application, for example. Microsoft provides the following AI models (see Fig. 8):
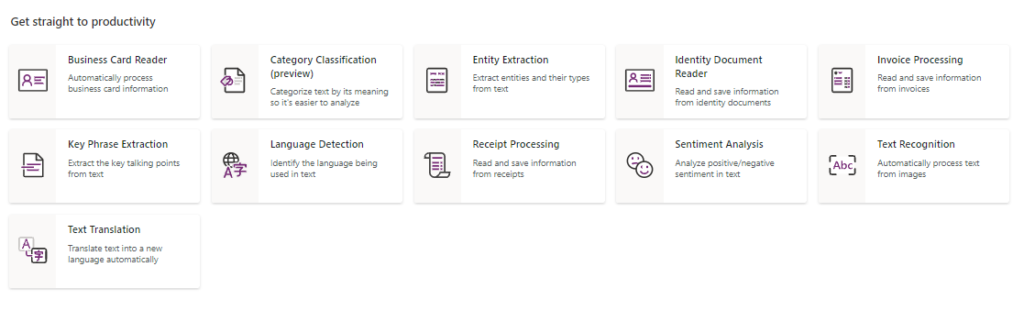
Fig. 8 AI Builder pre-built models
Business Card Reader extracts information such as name, job title, e-mail address, company name and phone numbers from business card images. Due to the great variety in business card design and format, the results are not always accurate, though Microsoft is still working on improving these mechanisms. When using this model, double-check that the data is correct. The model currently supports only English.
Category Classification (preview version) is a new AI model, only a preview feature, configured to classify text into categories useful for a specific business scenario. The pilot classification model was based on customer feedback, and additional classifications are planned for the future. The supported languages include English, French, German, Portuguese, Italian, Spanish and Chinese.
Entity Extraction pulls business-relevant data from a text. The most important elements are identified and sorted into predefined categories. The supported languages are English, French, German, Portuguese, Italian, Spanish and Chinese.
ID Card Reader extracts information from passports and US-issued driving licenses—given name, surname, gender, date of birth, state, country, nationality, street, ID number, and expiration date. The supported file formats, to a maximum size of 20 MB, are .jpg, .png and .pdf.
Key Phrase Extraction identifies the main points in a text document and can extract a list of key phrases from unstructured text documents. Supported languages include Danish, German, English, Spanish, Finnish, French, Italian, Japanese, Korean, Dutch, Norwegian, Polish, Portuguese (Brazil), Portuguese (Portugal), Russian, Swedish. Documents cannot exceed 5,120 characters with spaces.
Language Detection analyzes a text document to identify its predominant language. The result is a number between 0 and 1 followed by the detected language, such as “en”. The number indicates the model’s certainty that the result is correct, with 1 meaning complete certainty. The model supports language services in accordance with Text Analytics API v3 cognitive services.
Receipt Processing uses OCR technology to identify key information on scanned receipts. English-language sales documents from Australia, Canada, United States, United Kingdom and India are supported. The file requirements are the same for invoice processing, though this model only processes the first 200 pages of a PDF file.
Sentiment Analysis detects positive or negative feedback in text data such as social media, reviews, news, etc. It returns the feedback values as Positive, Negative, Neutral, or Mixed. The languages supported are German, Spanish, English, French, Hindi, Italian, Japanese, Korean, Dutch, Norwegian, Portuguese (Brazil), Portuguese (Portugal), Turkish, Chinese (simplified), and Chinese (traditional).
Text Recognition uses OCR technology to detect printed and handwritten text in processed images. The result of batch processing is a list of lines extracted from the input text. The supported file types are .jpg, .png, .bmp, and .pdf, with a maximum collective size of 20 MB. Check the list of supported languages.
Text Translation works in real-time to translate between more than 60 languages. It can also detect the language of the text data to be translated. The model supports language services in accordance with Text Analytics API v3 cognitive services.
AI Builder—Power Automate and Power Apps
Any models created with AI Builder can be used in both Power Apps and Power Automate applications. To do so, select the type of model to be used application, and then configure it with the appropriate wizard.
The Power Apps module provides two ways to use AI mechanisms. One, by typing the formula on the bar (see Fig. 9):
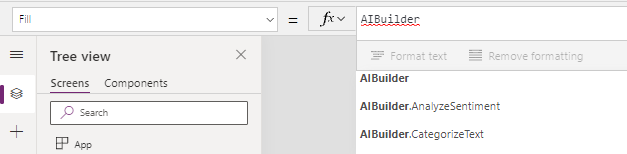
Fig. 9 AI Builder in Power Apps—formula
And two, by inserting a Power Apps component (see Fig. 10):
Fig. 10 AI Builder in Power Apps—component
The models available with formulas are Opinion Analysis, Entity Extraction, Key Phrase Extraction, Language Detection and Category Classification. The components available are Business Card Reader (canvas and model-driven applications), Receipt Processing, Form Processing, Image Detector and Text Recognition (all of the latter are canvas applications).
It is easy to call up and process the trained and published models with Power Automate flows. Just add the appropriate AI Builder connector to the flow and select a model (see Fig. 11):
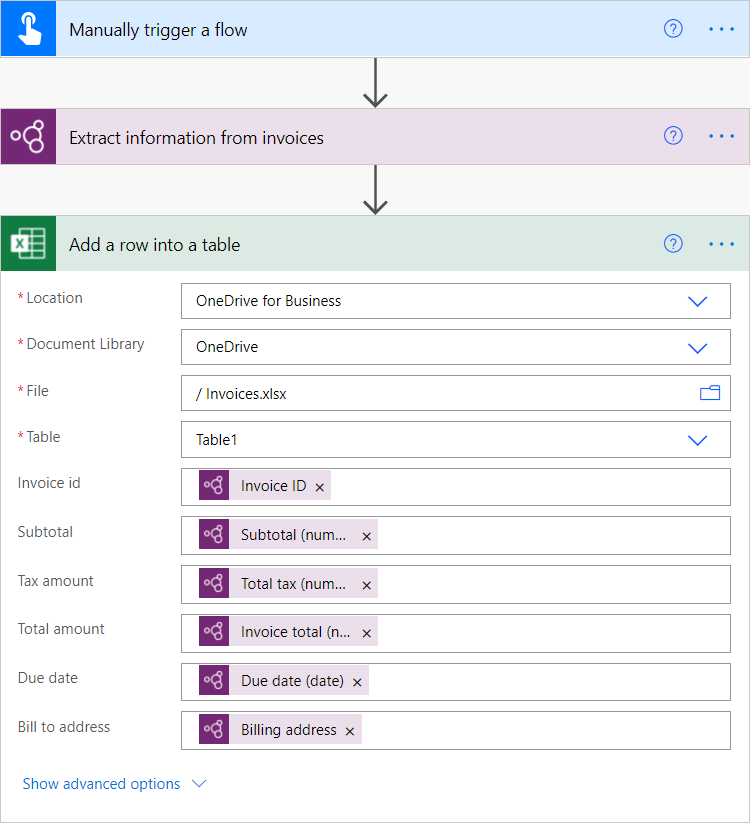
Fig. 11 AI Builder in Power Automate flow
The Power Automate service can integrate ready-made predefined models such as Business Card Reader, Category Classification, Entity Extraction, ID Card Reader, Key Phrase Extraction, Language Detection, Receipt Processing, Opinion Analysis, Text Recognition and Text Translation. We can also use custom-made models such as Category Classification, Entity Extraction, Form Processing, Object Detection, and Prediction.
Final thoughts
Artificial intelligence components in our applications and business processes can significantly accelerate and improve their capabilities. As we have seen, the tools described here offer many possibilities in terms of automating entry processes for documents such as invoices, contracts and forms. AI mechanisms can improve our communication with clients and analyze the content of our websites and social media. They can also significantly facilitate the work of sales representatives and service technicians by quickly identifying various types of objects.
The most important element is taking the time to select the right model (prepare quality input data, conduct appropriate training, and then analyze the results to improve the algorithm. It takes only a few training processes for the AI model to understand how to extract key information into metadata, which can then be added to a database, a legacy system, a workflow or any other business process. Anyone from the business environment can take the few necessary simple steps to a well-integrated solution (see Fig. 12):
Fig. 12 AI Builder—project lifecycle
This isn’t to say that there is no expertise involved. Rather, knowledge in a specific business will be of great importance in the entire process. In fact, such knowledge workers may become “AI trainers” in the near future rather than data entry workers. Of course, the participation of people in the whole process is invaluable because the machines will do what they do best—process, sort, and analyze (business) data. Nevertheless, the resulting conclusions will always require people to make decisions, select from among proposed options, or make further recommendations.






