

Although companies like OpenAI and Google do not disclose the specific training costs for state-of-the-art AI models such as GPT-4 and Gemini, it’s evident that these costs are significant and escalate as the models grow larger, more complex, and more capable.
For example, when OpenAI released GPT-3 in 2020, the cloud service provider Lambda estimated the training cost for this 175 million parameter model at over $4.6 million. The details regarding the size of GPT-4, which was launched a year later, remain unconfirmed, but estimates suggest it has between 1 trillion and 1.8 trillion parameters. OpenAI’s CEO Sam Altman has indicated that the training expenses for GPT-4 were “more than” $100 million. Furthermore, Anthropic’s CEO Dario Amodei has forecasted that by the end of this year, we might see models whose training costs exceed $1 billion, potentially rising to $10 billion by 2025.
Given the soaring costs associated with training Large Language Models (LLMs)—in terms of computational power, necessary hardware, and energy consumption—many researchers and companies are exploring alternative strategies to enhance model performance while managing expenses. One promising approach is the adoption of Small Language Models (SLMs). In this article, you will learn what SLMs are, how they differ from their larger counterparts, and the business scenarios and environments where they prove most beneficial.
Read more on AI:
AI in manufacturing: Four nonobvious implementations
Ten business use cases for generative AI virtual assistants
Generative AI in knowledge management—a practical solution for enterprises
Is ChatGPT dreaming of conquering the world? Generative AI in business
The power of generative AI at your fingertips—Azure OpenAI Service
Unleash your superpowers with new Power Platform AI capabilities
Curbing ChatGPT hallucinations with retrieval augmented generation (RAG)
Large language models (LLMs)—a simple introduction
Generative AI implementation in business: how to do it responsibly and ethically
What are small language models?
When it comes to generative AI, sometimes less is indeed more. Small language models (SLMs) are proving that they can be more effective and efficient for specific tasks compared to their larger counterparts, known as large language models (LLMs). SLMs are not only less costly to train and maintain but often surpass LLMs in performance due to their focused capabilities.
A small language model is a type of machine-learning algorithm trained on a dataset that is smaller, more specific, and often of higher quality than those used for LLMs. These models possess significantly fewer parameters—a measure of the complexity of the model—and a simpler architecture. Despite their size, SLMs are capable of understanding and generating human-like text, similar to LLMs which are trained on vast amounts of data.
SLMs are typically deployed for specialized tasks such as answering customer inquiries about a specific product, summarizing sales calls, or crafting marketing emails. Thanks to their small size and targeted training data, SLMs operate with greater computational efficiency and speed. This not only saves time and money but also improves accuracy, allowing businesses to integrate these specialized models seamlessly into their operations.
It is also important to note that small language models are not intended for tasks like researching healthcare trends or discovering new cancer treatments. These complex challenges require a level of creativity that goes beyond the capabilities of SLMs. However, SLMs are quite effective in more defined roles such as helping a healthcare company respond to customer inquiries about a specific program, like diabetes prevention.
Small language models vs. large language models
Let us compare Small Language Models (SMLs) and Large Language Models (LLMs) in a more detailed way.
Size and complexity:
- SLMs: Feature fewer parameters, typically fewer than 100 million. This smaller size contributes to simpler neural architectures. Small language models represent a significant shift in the AI landscape, emphasizing efficiency and accessibility.
- LLMs: Possess a vastly larger number of parameters, often ranging from hundreds of millions to over a hundred billion. Their complex architectures enable more creative and intricate tasks.
Training data and time:
- SLMs: Require significantly less training data and can be trained relatively quickly—often within minutes or hours. The actual training time can vary depending on the model’s architecture and efficiency. While large language models often utilize transfer learning, small language models are typically trained from scratch, focusing on efficiency and specific tasks.
- LLMs: Need vast amounts of data and extensive computational resources, with training times spanning several days to weeks.
Resource efficiency:
- SLMs: Consume fewer computing resources, making them ideal for environments with limited computational capabilities. They are cost-effective and easier to deploy on smaller-scale systems. SLMs can also process data locally, making them ideal for environments with stringent privacy and security regulations.
- LLMs: Demand substantial computational power and storage, leading to higher operational costs and increased energy consumption. They are typically operated on specialized hardware in data centers.
Application suitability:
- SLMs: Best suited for applications where the complexity of the task is low and computational resources are scarce. Common uses include embedded systems, mobile apps, and lightweight chatbots. SLMs are also used in chatbots and virtual assistants to conduct natural and engaging conversations, especially in customer service applications.
- LLMs: Excel in tasks that require deep linguistic understanding and creativity such as advanced conversational AI, content creation, and complex problem-solving. They are often utilized in research and large-scale commercial AI applications.
Accuracy and capabilities:
- SLMs: While capable of handling basic language tasks adequately, their simpler models may struggle with more complex language understanding and generation.
- LLMs: Provide higher accuracy and more sophisticated language capabilities, handling intricate nuances and context better due to their larger scale and training depth.
Deployment and scalability:
- SLMs: Easier and faster to deploy, particularly in scenarios where rapid development and deployment are crucial. They effectively scale down to smaller applications.
- LLMs: While deployment can be challenging due to their size, they scale up well and are adept at handling high-demand environments, benefiting from economies of scale in larger systems.
Cost of training:
- SLMs: Typically incur lower training costs due to their reduced data and computational demands, making them more accessible and economical for smaller projects or organizations with limited budgets.
- LLMs: Training these models is considerably more expensive. They require more data and computational power, which increases operational expenses. Specialized hardware and longer training periods also contribute to higher energy costs, making LLMs more suitable for well-funded enterprises or research institutions.
You can find all the above points summarized in Table 1 below:
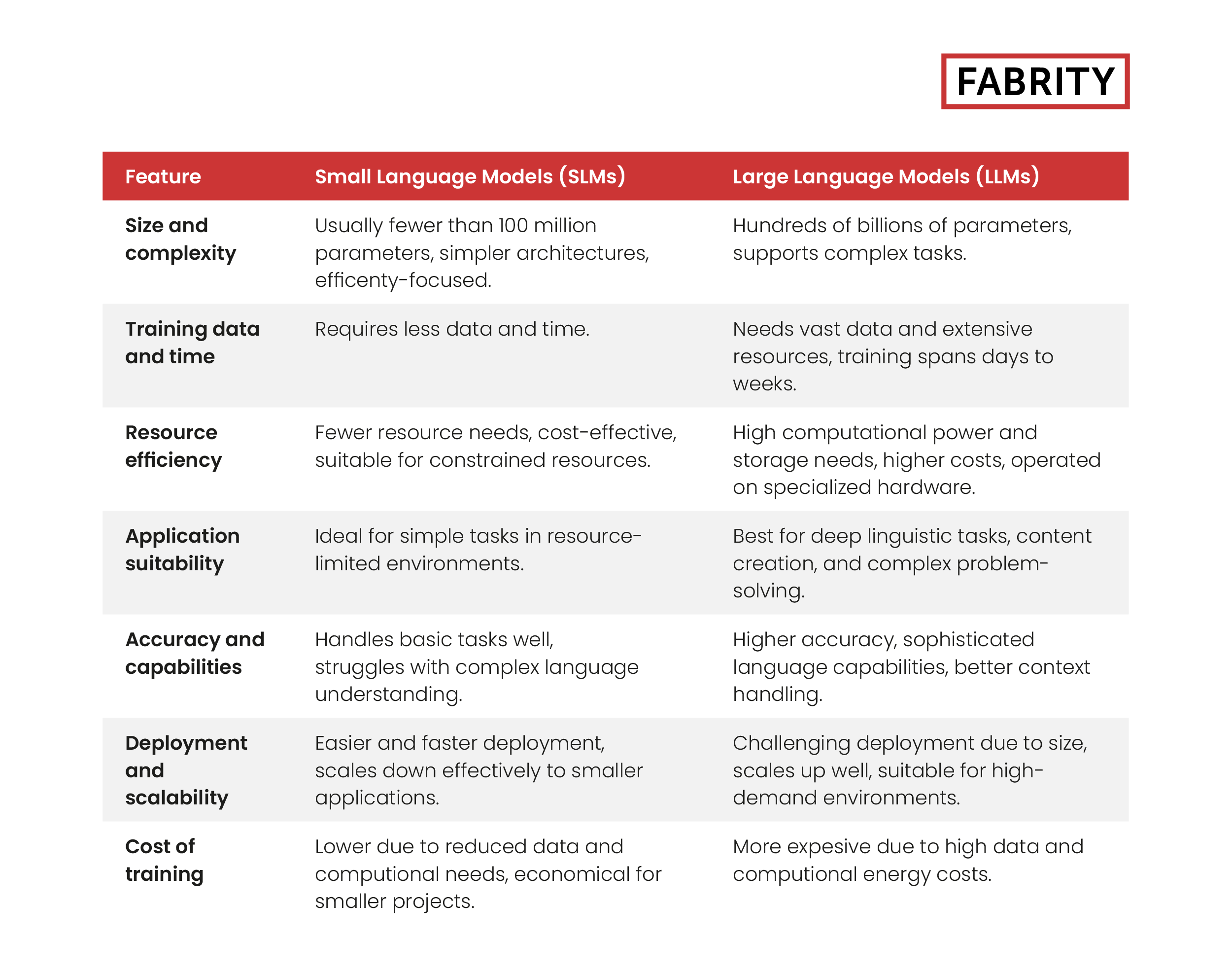
Tab. 1. SLMs vs. LLMs
When small language models can be a viable option
Small language models are especially useful in business contexts where efficiency, cost, and data privacy are key priorities. Here is an in-depth look at when and why businesses might choose to use small language models: SLMs, when fine-tuned for specific domains, can achieve language understanding close to LLMs, demonstrating their capability in various natural language processing tasks.
Specific, limited-scope language tasks
- Targeted applications: SLMs are particularly effective in scenarios where language processing needs are precise and well-defined, such as parsing legal documents, analyzing customer feedback, or managing domain-specific inquiries. They are also valuable in analyzing market trends to optimize sales and marketing strategies.
- Customization: Thanks to their manageable size, SLMs can be easily tailored and fine-tuned to specific datasets, allowing businesses to achieve high accuracy in specialized tasks without the complexity of larger models.
Fast and efficient language processing
- Real-time interactions: Businesses that need instant language processing like interactive chatbots, immediate customer support, or live translation services, benefit from the quicker response times offered by SLMs.
- Lower latency: Deploying SLMs on local servers or even edge devices minimizes the latency often associated with cloud-based processing, making them ideal for speed-critical applications.
Sensitivity to operational costs and resource usage
- Reduced infrastructure requirements: SLMs are appealing to companies looking to minimize costs since they need significantly less computational power and can function on less specialized hardware.
- Economic efficiency: By significantly reducing expenses related to data processing and storage, SLMs provide a cost-effective solution for startups, medium-sized companies, or businesses with limited IT budgets.
High value on data privacy
- Local data processing: In sectors like healthcare and finance where data privacy is crucial, SLMs offer the benefit of being fully operable in-house. Local data processing ensures that sensitive information remains within the organizational boundary.
- Compliance with regulations: For organizations required to adhere to strict data protection laws such as GDPR or HIPAA, SLMs are advantageous as they aid in maintaining strict control over data handling and storage practices.

Examples of small language models
- DistilBERT: Developed by Hugging Face, this model is a condensed version of BERT, retaining 97% of its language understanding capabilities, however, it is 60% faster and 40% smaller. It is highly effective for sentiment analysis, text classification, and question-answering tasks.
- ALBERT (A Lite BERT): An optimized version of BERT from Google Research, ALBERT reduces model size through parameter sharing and factorization techniques, excelling in natural language inference, sentence classification, and reading comprehension.
- TinyBERT: Achieved through model distillation, TinyBERT is a smaller version of BERT offering a balance between performance and efficiency, making it suitable for mobile and edge devices for applications like real-time text processing.
- MobileBERT: Specifically designed for mobile devices, MobileBERT is a compact version optimized for performance on resource-constrained hardware, used for voice assistants, on-device language understanding, and mobile NLP applications.
- MiniLM: Developed by Microsoft, this model uses deep self-attention distillation to maintain competitive performance with minimal computational overhead, ideal for large-scale web search, document ranking, and lightweight NLP services.
- Phi-3 Mini: Developed by Microsoft, this model is part of the Phi-3 family of small language models, designed for a variety of applications in language processing, reasoning, coding, and math.
The future of small language models
Of course, the rise of SLMs does not imply that the development of large language models will cease. In fact, we can anticipate that new LLMs will be larger and more capable than ever. From GPT-4 onward, it is more accurate to talk about multimodal models capable of processing a wide variety of inputs, including text, images, and audio. These models can transform these inputs into various outputs, not just replicate the original type. Large models excel at complex tasks involving advanced reasoning, data analysis, and understanding context.
However, SLMs also have a significant role. In some business scenarios, using LLMs would be excessive. Not every task demands vast capabilities, and sometimes, they are impractical due to limited computational power or network connectivity. Small language models perform well in simpler, clearly defined tasks, and are more accessible for organizations with limited resources. They can also be fine-tuned more easily to meet specific needs.
Consider the use of SLMs “at the network edge”—on mobile devices like smartphones, car computers, PCs without Wi-Fi, traffic systems, smart sensors on factory floors, or remote cameras. In these settings, obtaining quick responses is crucial, so minimizing latency—the delay in data communication over a network when prompts are sent and responses awaited—is essential.
In highly regulated industries such as life sciences or banking, SLMs enable organizations to maintain strict control over data management and storage. Sometimes, data cannot be sent to the cloud and must be processed on-premises. SLMs, designed to be lightweight and efficient without requiring substantial computing resources, can be viable options for organizations with strict data protection requirements.
In summary, I believe we are moving towards a diverse portfolio of AI models, from which organizations will choose what best suits their specific needs. Not all generative AI solutions will be powered by large models; instead, we will see a mix of different models and their applications, with SLMs performing specific, well-defined tasks.
Lastly, synthetic data appears to be a major enabler for the further development of SLMs. Generated by deep learning algorithms, synthetic data uses existing data samples to learn correlations, statistical properties, and structures. Once trained, these algorithms can produce data that is statistically and structurally identical to the original training data, but entirely synthetic. This approach, also employed by Microsoft in their Phi-3 model family, opens up vast possibilities for training SLMs. Equipped with synthetic data, small language models can perform exceptionally well and quickly in specific tasks, paving the way for nearly limitless potential business applications.






